ACS2 in Maze¶
This notebook presents how to integrate ACS2 algorithm with maze environment (using OpenAI Gym interface).
Begin with attaching required dependencies. Because most of the work is by now done locally no PIP modules are used (just pure OS paths)
[1]:
# General
from __future__ import unicode_literals
%matplotlib inline
import numpy as np
import pandas as pd
import matplotlib
import matplotlib.pyplot as plt
# To avoid Type3 fonts in generated pdf file
matplotlib.rcParams['pdf.fonttype'] = 42
matplotlib.rcParams['ps.fonttype'] = 42
# Logger
import logging
logging.basicConfig(level=logging.WARN)
# ALCS + Custom environments
import sys, os
sys.path.append(os.path.abspath('../'))
# Enable automatic module reload
%load_ext autoreload
%autoreload 2
# Load PyALCS module
from lcs.agents.acs2 import ACS2, Configuration, ClassifiersList
# Load environments
import gym
import gym_maze
Environment - Maze¶
We are going to look at provided mazes. Their names starts with “Maze…” or “Woods…” so see what is possible to load:
[2]:
# Custom function for obtaining available environments
filter_envs = lambda env: env.id.startswith("Maze") or env.id.startswith("Woods")
all_envs = [env for env in gym.envs.registry.all()]
maze_envs = [env for env in all_envs if filter_envs(env)]
for env in maze_envs:
print("Maze ID: [{}], non-deterministic: [{}], trials: [{}]".format(
env.id, env.nondeterministic, env.trials))
Maze ID: [MazeF1-v0], non-deterministic: [False], trials: [100]
Maze ID: [MazeF2-v0], non-deterministic: [False], trials: [100]
Maze ID: [MazeF3-v0], non-deterministic: [False], trials: [100]
Maze ID: [MazeF4-v0], non-deterministic: [True], trials: [100]
Maze ID: [Maze4-v0], non-deterministic: [False], trials: [100]
Maze ID: [Maze5-v0], non-deterministic: [False], trials: [100]
Maze ID: [Maze6-v0], non-deterministic: [True], trials: [100]
Maze ID: [Woods1-v0], non-deterministic: [False], trials: [100]
Maze ID: [Woods14-v0], non-deterministic: [False], trials: [100]
Let’s see how it looks in action. First we are going to initialize new environment using gym.make() instruction from OpenAI Gym.
[3]:
#MAZE = "Woods14-v0"
MAZE = "Maze5-v0"
# Initialize environment
maze = gym.make(MAZE)
# Reset it, by putting an agent into random position
situation = maze.reset()
# Render the state in ASCII
maze.render()
■ ■ ■ ■ ■ ■ ■ ■ ■
■ □ □ □ □ □ □ $ ■
■ □ □ ■ □ ■ ■ □ ■
■ □ ■ □ □ □ □ □ ■
■ □ □ □ ■ ■ □ □ ■
■ □ ■ □ ■ □ □ ■ ■
■ □ ■ □ □ ■ □ □ ■
■ □ A □ □ □ ■ □ ■
■ ■ ■ ■ ■ ■ ■ ■ ■
The reset() function puts an agent into random position (on path inside maze) returning current perception.
The perception consists of 8 values representing N, NE, E, SE, S, SW, W, NW directions. It outputs 0 for the path, 1 for the wall and 9 for the reward.
[4]:
# Show current agents perception
situation
[4]:
('1', '0', '0', '1', '1', '1', '0', '0')
We can interact with the environment by performing actions.
Agent can perform 8 actions - moving into different directions.
To do so use step(action) function. It will return couple interesting information: - new state perception, - reward for executing move (ie. finding the reward) - is the trial finish, - debug data
[5]:
ACTION = 0 # Move N
# Execute action
state, reward, done, _ = maze.step(ACTION)
# Show new state
print(f"New state: {state}, reward: {reward}, is done: {done}")
# Render the env one more time after executing step
maze.render()
New state: ('1', '0', '0', '1', '1', '1', '0', '0'), reward: 0, is done: False
■ ■ ■ ■ ■ ■ ■ ■ ■
■ □ □ □ □ □ □ $ ■
■ □ □ ■ □ ■ ■ □ ■
■ □ ■ □ □ □ □ □ ■
■ □ □ □ ■ ■ □ □ ■
■ □ ■ □ ■ □ □ ■ ■
■ □ ■ □ □ ■ □ □ ■
■ □ A □ □ □ ■ □ ■
■ ■ ■ ■ ■ ■ ■ ■ ■
Agent - ACS2¶
First provide a helper method for calculating obtained knowledge
[6]:
def _maze_knowledge(population, environment) -> float:
transitions = environment.env.get_all_possible_transitions()
# Take into consideration only reliable classifiers
reliable_classifiers = [c for c in population if c.is_reliable()]
# Count how many transitions are anticipated correctly
nr_correct = 0
# For all possible destinations from each path cell
for start, action, end in transitions:
p0 = environment.env.maze.perception(*start)
p1 = environment.env.maze.perception(*end)
if any([True for cl in reliable_classifiers
if cl.predicts_successfully(p0, action, p1)]):
nr_correct += 1
return nr_correct / len(transitions) * 100.0
[7]:
from lcs.metrics import population_metrics
def _maze_metrics(pop, env):
metrics = {
'knowledge': _maze_knowledge(pop, env)
}
# Add basic population metrics
metrics.update(population_metrics(pop, env))
return metrics
Exploration phase¶
[8]:
CLASSIFIER_LENGTH=8
NUMBER_OF_POSSIBLE_ACTIONS=8
# Define agent's default configuration
cfg = Configuration(
classifier_length=CLASSIFIER_LENGTH,
number_of_possible_actions=NUMBER_OF_POSSIBLE_ACTIONS,
metrics_trial_frequency=1,
user_metrics_collector_fcn=_maze_metrics)
# Define agent
agent = ACS2(cfg)
[9]:
%%time
population, metrics = agent.explore(maze, 100)
CPU times: user 5.19 s, sys: 11.7 ms, total: 5.2 s
Wall time: 5.22 s
We can take a sneak peek into a created list of classifiers. Let’s have a look at top 10:
[10]:
population.sort(key=lambda cl: -cl.fitness)
for cl in population[:10]:
print("{!r} \tq: {:.2f} \tr: {:.2f} \tir: {:.2f}".format(cl, cl.q, cl.r, cl.ir))
9####010 0 1####101 (empty) q: 0.963 r: 884.0 ir: 884.0 f: 851.7 exp: 41 tga: 645 talp: 2817 tav: 46.2 num: 1 q: 0.96 r: 884.02 ir: 884.02
9#1##010 0 1####101 (empty) q: 0.921 r: 809.5 ir: 806.3 f: 745.3 exp: 31 tga: 1682 talp: 2817 tav: 35.7 num: 1 q: 0.92 r: 809.54 ir: 806.29
##901### 2 ##110### (empty) q: 0.875 r: 762.2 ir: 762.2 f: 666.8 exp: 27 tga: 590 talp: 2875 tav: 79.1 num: 1 q: 0.87 r: 762.17 ir: 762.17
011###01 0 9#####10 (empty) q: 0.989 r: 563.2 ir: 0.0 f: 557.2 exp: 40 tga: 951 talp: 2817 tav: 43.4 num: 1 q: 0.99 r: 563.17 ir: 0.00
01##0#01 0 9#####10 (empty) q: 0.976 r: 563.2 ir: 0.0 f: 549.5 exp: 41 tga: 949 talp: 2817 tav: 42.7 num: 1 q: 0.98 r: 563.17 ir: 0.00
01110001 0 9#####10 (empty) q: 0.972 r: 563.0 ir: 0.0 f: 547.1 exp: 41 tga: 949 talp: 2817 tav: 41.3 num: 1 q: 0.97 r: 563.01 ir: 0.00
0#1##001 0 9#####10 (empty) q: 0.953 r: 553.8 ir: 0.0 f: 527.6 exp: 32 tga: 1769 talp: 2817 tav: 32.5 num: 1 q: 0.95 r: 553.76 ir: 0.00
1000#101 1 9111#010 (empty) q: 0.942 r: 347.8 ir: 0.0 f: 327.6 exp: 14 tga: 644 talp: 2795 tav: 1.46e+02 num: 1 q: 0.94 r: 347.78 ir: 0.00
1#0110## 2 ##90#1## (empty) q: 0.958 r: 290.4 ir: 0.0 f: 278.1 exp: 22 tga: 1168 talp: 2874 tav: 76.9 num: 1 q: 0.96 r: 290.39 ir: 0.00
11011001 2 ##90#1## (empty) q: 0.846 r: 290.3 ir: 0.0 f: 245.7 exp: 22 tga: 1168 talp: 2874 tav: 77.0 num: 1 q: 0.85 r: 290.33 ir: 0.00
Exploitation¶
Now we can either reuse our previous agent or initialize it one more time passing the initial population of classifiers as apriori knowledge.
[11]:
# Reinitialize agent using defined configuration and population
agent = ACS2(cfg, population)
[12]:
%%time
population, metrics = agent.exploit(maze, 1)
CPU times: user 33.3 ms, sys: 16 µs, total: 33.4 ms
Wall time: 33.4 ms
[13]:
metrics[-1]
[13]:
{'trial': 0,
'steps_in_trial': 2,
'reward': 1000,
'knowledge': 24.65753424657534,
'population': 419,
'numerosity': 419,
'reliable': 78}
Experiments¶
[14]:
def parse_metrics_to_df(explore_metrics, exploit_metrics):
def extract_details(row):
row['trial'] = row['trial']
row['steps'] = row['steps_in_trial']
row['numerosity'] = row['numerosity']
row['reliable'] = row['reliable']
row['knowledge'] = row['knowledge']
return row
# Load both metrics into data frame
explore_df = pd.DataFrame(explore_metrics)
exploit_df = pd.DataFrame(exploit_metrics)
# Mark them with specific phase
explore_df['phase'] = 'explore'
exploit_df['phase'] = 'exploit'
# Extract details
explore_df = explore_df.apply(extract_details, axis=1)
exploit_df = exploit_df.apply(extract_details, axis=1)
# Adjuts exploit trial counter
exploit_df['trial'] = exploit_df.apply(lambda r: r['trial']+len(explore_df), axis=1)
# Concatenate both dataframes
df = pd.concat([explore_df, exploit_df])
df.set_index('trial', inplace=True)
return df
For various mazes visualize - classifiers / reliable classifiers for steps - optimal policy - steps (exploration | exploitation) - knowledge - parameters setting
[15]:
def find_best_classifier(population, situation, cfg):
match_set = population.form_match_set(situation)
anticipated_change_cls = [cl for cl in match_set if cl.does_anticipate_change()]
if (len(anticipated_change_cls) > 0):
return max(anticipated_change_cls, key=lambda cl: cl.fitness)
return None
def build_fitness_matrix(env, population, cfg):
original = env.env.maze.matrix
fitness = original.copy()
# Think about more 'functional' way of doing this
for index, x in np.ndenumerate(original):
# Path - best classfier fitness
if x == 0:
perception = env.env.maze.perception(index[1], index[0])
best_cl = find_best_classifier(population, perception, cfg)
if best_cl:
fitness[index] = best_cl.fitness
else:
fitness[index] = -1
# Wall - fitness = 0
if x == 1:
fitness[index] = 0
# Reward - inf fitness
if x == 9:
fitness[index] = fitness.max () + 500
return fitness
def build_action_matrix(env, population, cfg):
ACTION_LOOKUP = {
0: u'↑', 1: u'↗', 2: u'→', 3: u'↘',
4: u'↓', 5: u'↙', 6: u'←', 7: u'↖'
}
original = env.env.maze.matrix
action = original.copy().astype(str)
# Think about more 'functional' way of doing this
for index, x in np.ndenumerate(original):
# Path - best classfier fitness
if x == 0:
perception = env.env.maze.perception(index[1], index[0])
best_cl = find_best_classifier(population, perception, cfg)
if best_cl:
action[index] = ACTION_LOOKUP[best_cl.action]
else:
action[index] = '?'
# Wall - fitness = 0
if x == 1:
action[index] = '\#'
# Reward - inf fitness
if x == 9:
action[index] = 'R'
return action
Plotting functions and settings¶
[16]:
# Plot constants
TITLE_TEXT_SIZE=24
AXIS_TEXT_SIZE=18
LEGEND_TEXT_SIZE=16
[17]:
def plot_policy(env, agent, cfg, ax=None):
if ax is None:
ax = plt.gca()
ax.set_aspect("equal")
# Handy variables
maze_countours = maze.env.maze.matrix
max_x = env.env.maze.max_x
max_y = env.env.maze.max_y
fitness_matrix = build_fitness_matrix(env, agent.population, cfg)
action_matrix = build_action_matrix(env, agent.population, cfg)
# Render maze as image
plt.imshow(fitness_matrix, interpolation='nearest', cmap='Reds', aspect='auto',
extent=[0, max_x, max_y, 0])
# Add labels to each cell
for (y,x), val in np.ndenumerate(action_matrix):
plt.text(x+0.4, y+0.5, "${}$".format(val))
ax.set_title("Policy", fontsize=TITLE_TEXT_SIZE)
ax.set_xlabel('x', fontsize=AXIS_TEXT_SIZE)
ax.set_ylabel('y', fontsize=AXIS_TEXT_SIZE)
ax.set_xlim(0, max_x)
ax.set_ylim(max_y, 0)
ax.set_xticks(range(0, max_x))
ax.set_yticks(range(0, max_y))
ax.grid(True)
[18]:
def plot_knowledge(df, ax=None):
if ax is None:
ax = plt.gca()
explore_df = df.query("phase == 'explore'")
exploit_df = df.query("phase == 'exploit'")
explore_df['knowledge'].plot(ax=ax, c='blue')
exploit_df['knowledge'].plot(ax=ax, c='red')
ax.axvline(x=len(explore_df), c='black', linestyle='dashed')
ax.set_title("Achieved knowledge", fontsize=TITLE_TEXT_SIZE)
ax.set_xlabel("Trial", fontsize=AXIS_TEXT_SIZE)
ax.set_ylabel("Knowledge [%]", fontsize=AXIS_TEXT_SIZE)
ax.set_ylim([0, 105])
[19]:
def plot_steps(df, ax=None):
if ax is None:
ax = plt.gca()
explore_df = df.query("phase == 'explore'")
exploit_df = df.query("phase == 'exploit'")
explore_df['steps'].plot(ax=ax, c='blue', linewidth=.5)
exploit_df['steps'].plot(ax=ax, c='red', linewidth=0.5)
ax.axvline(x=len(explore_df), c='black', linestyle='dashed')
ax.set_title("Steps", fontsize=TITLE_TEXT_SIZE)
ax.set_xlabel("Trial", fontsize=AXIS_TEXT_SIZE)
ax.set_ylabel("Steps", fontsize=AXIS_TEXT_SIZE)
[20]:
def plot_classifiers(df, ax=None):
if ax is None:
ax = plt.gca()
explore_df = df.query("phase == 'explore'")
exploit_df = df.query("phase == 'exploit'")
df['numerosity'].plot(ax=ax, c='blue')
df['reliable'].plot(ax=ax, c='red')
ax.axvline(x=len(explore_df), c='black', linestyle='dashed')
ax.set_title("Classifiers", fontsize=TITLE_TEXT_SIZE)
ax.set_xlabel("Trial", fontsize=AXIS_TEXT_SIZE)
ax.set_ylabel("Classifiers", fontsize=AXIS_TEXT_SIZE)
ax.legend(fontsize=LEGEND_TEXT_SIZE)
[21]:
def plot_performance(agent, maze, metrics_df, cfg, env_name):
plt.figure(figsize=(13, 10), dpi=100)
plt.suptitle(f'ACS2 Performance in {env_name} environment', fontsize=32)
ax1 = plt.subplot(221)
plot_policy(maze, agent, cfg, ax1)
ax2 = plt.subplot(222)
plot_knowledge(metrics_df, ax2)
ax3 = plt.subplot(223)
plot_classifiers(metrics_df, ax3)
ax4 = plt.subplot(224)
plot_steps(metrics_df, ax4)
plt.subplots_adjust(top=0.86, wspace=0.3, hspace=0.3)
Maze5¶
[22]:
%%time
# define environment
maze5 = gym.make('Maze5-v0')
# explore
agent_maze5 = ACS2(cfg)
population_maze5_explore, metrics_maze5_explore = agent_maze5.explore(maze5, 3000)
# exploit
agent_maze5 = ACS2(cfg, population_maze5_explore)
_, metrics_maze5_exploit = agent_maze5.exploit(maze5, 400)
CPU times: user 7min 2s, sys: 876 ms, total: 7min 3s
Wall time: 7min 4s
[23]:
maze5_metrics_df = parse_metrics_to_df(metrics_maze5_explore, metrics_maze5_exploit)
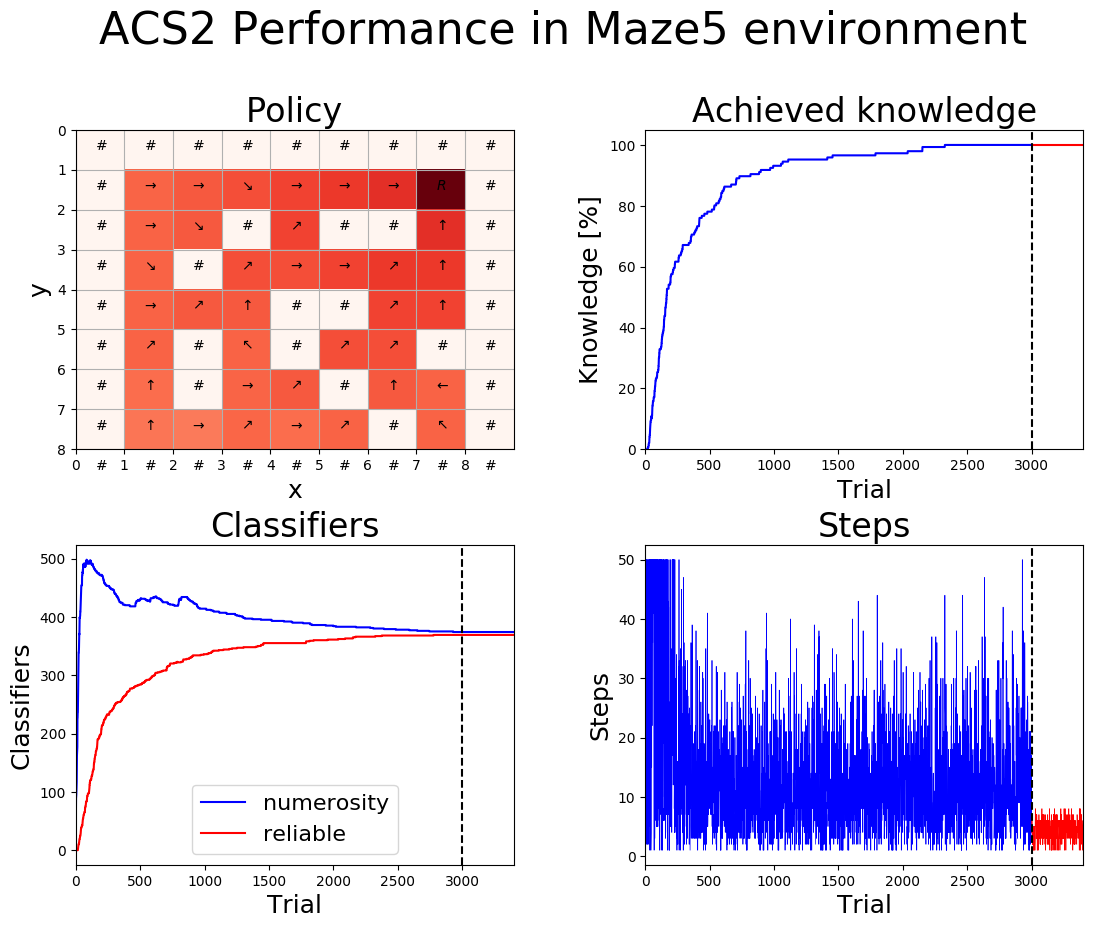
[24]:
plot_performance(agent_maze5, maze5, maze5_metrics_df, cfg, 'Maze5')
Woods14¶
[25]:
%%time
# define environment
woods14 = gym.make('Woods14-v0')
# explore
agent_woods14 = ACS2(cfg)
population_woods14_explore, metrics_woods14_explore = agent_woods14.explore(woods14, 1000)
# exploit
agent_woods14 = ACS2(cfg, population_woods14_explore)
_, metrics_woods14_exploit = agent_woods14.exploit(woods14, 200)
CPU times: user 32.1 s, sys: 62.5 ms, total: 32.2 s
Wall time: 32.3 s
[26]:
woods14_metrics_df = parse_metrics_to_df(metrics_woods14_explore, metrics_woods14_exploit)
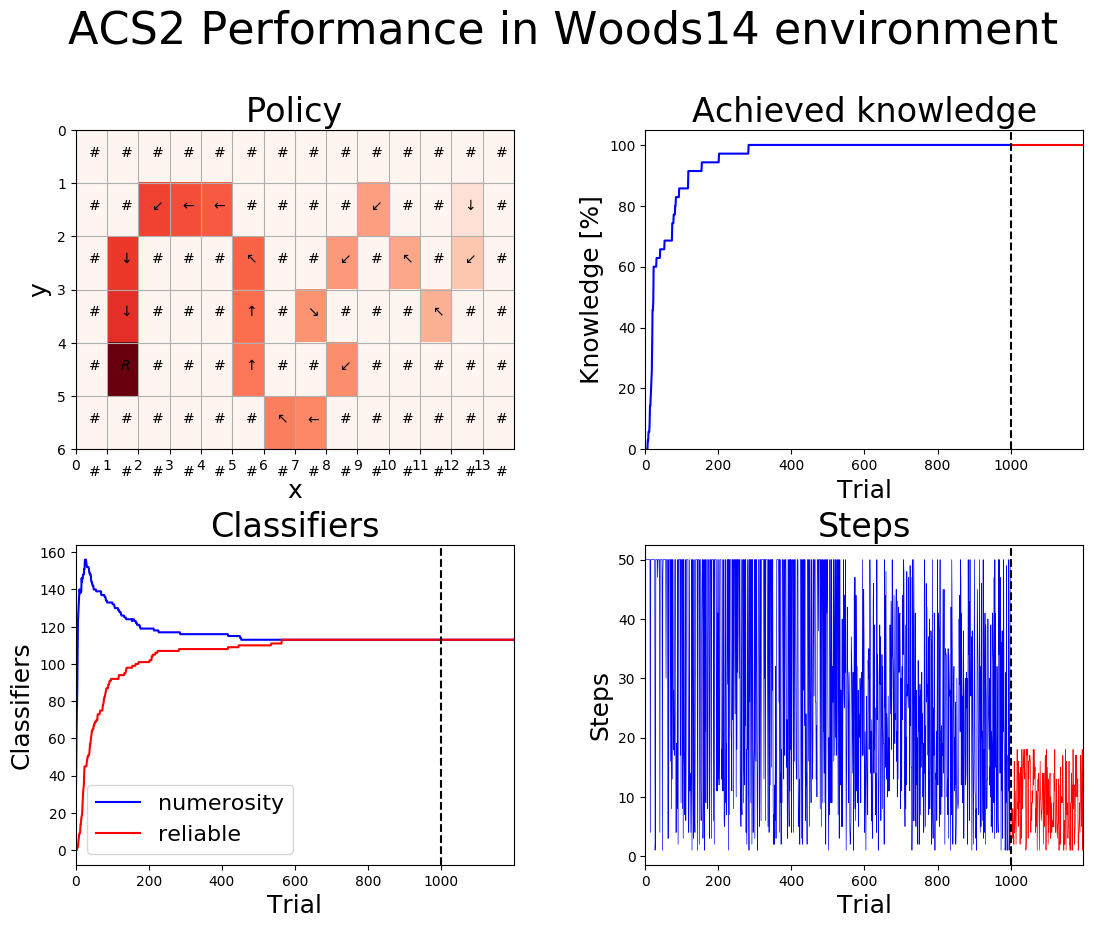
[27]:
plot_performance(agent_woods14, woods14, woods14_metrics_df, cfg, 'Woods14')